
Objectif
Vous permettre de comprendre comment est calculé le potentiel d’amélioration des revenus affiché dans le lab.
Pré-requis
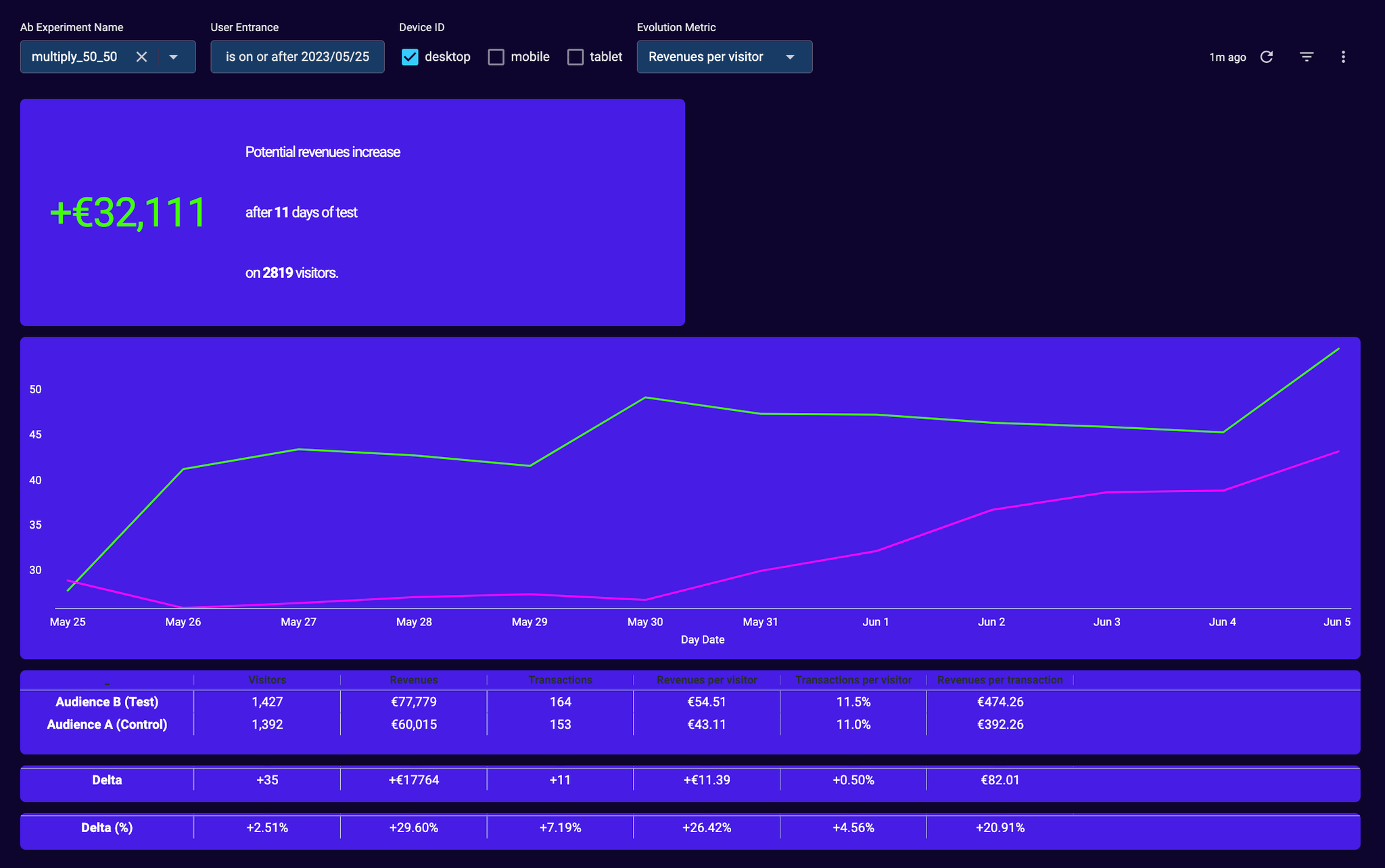
Choisir les bons filtres et la bonne période !
A savoir :
- le bon nom d’expérimentation (dans l’exemple ci-dessus, multiply_50_50)
- la bonne date de début du test (dans l’exemple ci-dessus le 25 mai 2023, soit un jour après la mise en production)
Si la mesure se fait sur une période trop courte (les 7 derniers jours par exemple), vous ne mesurez les résultats que sur une petite portion de vos visiteurs, et le résultat ainsi échantillonné est rarement significatif. Le potentiel risque de varier très fortement d’un jour à l’autre, de la même manière que si vous tirez un dé A et un dé B une fois par jour, si vous comparez le tirage du jour de A versus B vous allez en tirer des conclusions qui risquent d’être contradictoires avec celles de la veille. En revanche, sur une période assez longue vous découvrirez si les dés sont identiques, ou l’un d’eux est pipé.
Il convient de sélectionner la date du jour qui suit la date de mise en ligne du test, afin de ne pas inclure des données (visite, pages vues, transactions, revenus,…) concernant des visiteurs qui auraient visité le site le jour de la mise en ligne mais AVANT que le test ne soit visible
- un type d’appareil ou device (ici desktop)
En analysant les résultats par type d’appareil, vous êtes certains de ne pas vous tromper, et de comparer des audiences comparables.
Si vous souhaitez afficher les résultats pour l’ensemble des types d’appareils :
- le potentiel est juste (c’est bien la somme du potentiel par type d’appareil)
- les valeurs dans le tableau sont justes mais confusantes car elles ne corrigent pas des effets de mix entre les différents types d’appareil dans chaque groupe A et B : les valeurs moyennes de revenus par visiteur varient très fortement suivant le type d’appareil, et l’on ne voit pas dans ce tableau la répartition des visiteurs par type d’appareil
Attendre suffisamment longtemps
La significativité
La significativité de l’expérience n’est pas encore calculée par défaut dans Potions Lab.
Il existe plusieurs calculateurs pour AB tester l’éventuelle amélioration du nombre de transactions par visiteur mais le réel calculateur que nous nous apprêtons à mettre en place est celui qui permet de comparer la distribution de valeurs de paniers dans A versus la distribution des valeurs de panier dans B.
La méthodologie du futur test est détaillée ici : https://www.evanmiller.org/ab-testing/t-test.html
Même si un test n’est pas forcément significatif et qu’il ne l’est qu’au bout de très longtemps, s’il vous fait gagner de l’argent sur la durée du test… C’est déjà un bon signe.
La période transitoire
La valeur par utilisateur augmente dans le temps jusqu’à stagner.
Il est préférable d’attendre que la valeur par utilisateur n’augmente plus trop pour évaluer correctement son AB Test.
Sans attendre la fin de cette période transitoire vous pourriez préférer une solution qui “accélère” l’achat mais ne l’augmente pas sur le long terme.
Suivant la nature de l’AB test, son impact peut être immédiat sur la transaction ou plus lointain.
Une bannière de recommandations au moment de l’ajout panier est plus proche de l’achat d’un visiteur, qu’une bannière sur une page produit. Il y a donc de grandes chances, que si le visiteur achète finalement un produit recommandé, il le fasse dans la même transaction que le produit qu’il vient d’ajouter au panier.
Une bannière de recommandations sur une fiche produit peut influer sur des achats à très court terme ou à plus longue échéance.
Ce délai entre l’entrée dans l’audience A ou B (la vue d’une bannière de recommandation ou non par exemple) et l’objectif (ici la transaction) a pour effet d’introduire un “régime transitoire” plus ou moins long dans les résultats.
Prenons 100 visiteurs d’un site, entrés le 1er janvier dans l’audience B, qui voient des bannières de recommandations. Au total, ces visiteurs génèrent 15€ de revenus le 1er janvier puis 10€ de revenus le 2 janvier, puis 10€ de revenus le 3 janvier, puis 5€ le 4 janvier, puis plus rien.
La valeur par visiteur de cette “cohorte” augmente donc progressivement :
- 0.15€ le 1er janvier (15€)/100
- 0.25€ le 2 janvier (15€+10€)/100
- 0.35€ le 3 janvier (15€+10€+10€)/100
- 0.40€ le 4 janvier (20€+10€+10€+5€)/100
Prenons maintenant la cohorte A qui, elle, a dépensé au total 20€ le 1er janvier, puis 10€ puis 5€.
La valeur par utilisateur pour cette cohorte est de
- 0.20€ le 1er janvier (20€)/100
- 0.30€ le 2 janvier (20€+10€)/100
- 0.35€ le 3 janvier (20€+10€+5€)/100
- 035€ le 4 janvier (20€+10€+5€)/100 car il n’y a plus d’achat.
Si l’on comparait ces deux courbes au 1er ou au 2 janvier on conclurait que A est meilleur que B, alors qu’en réalité sur le long terme l’expérience du groupe B génère plus de revenus.
On comprend que cette période transitoire est d’autant plus longue que l’entrée dans une audience est éloignée dans le temps du succès à suivre.
Calcul du potentiel
Le calcul du potentiel est effectué par type d’appareil et sommé si les filtres contiennent plusieurs appareils.
Si l’on reprend cet exemple, le calcul du potentiel est très simple =
revenus si l’ensemble des visiteurs étaient dans l’audience B
moins les revenus si l’ensemble des visiteurs étaient dans l’audience A
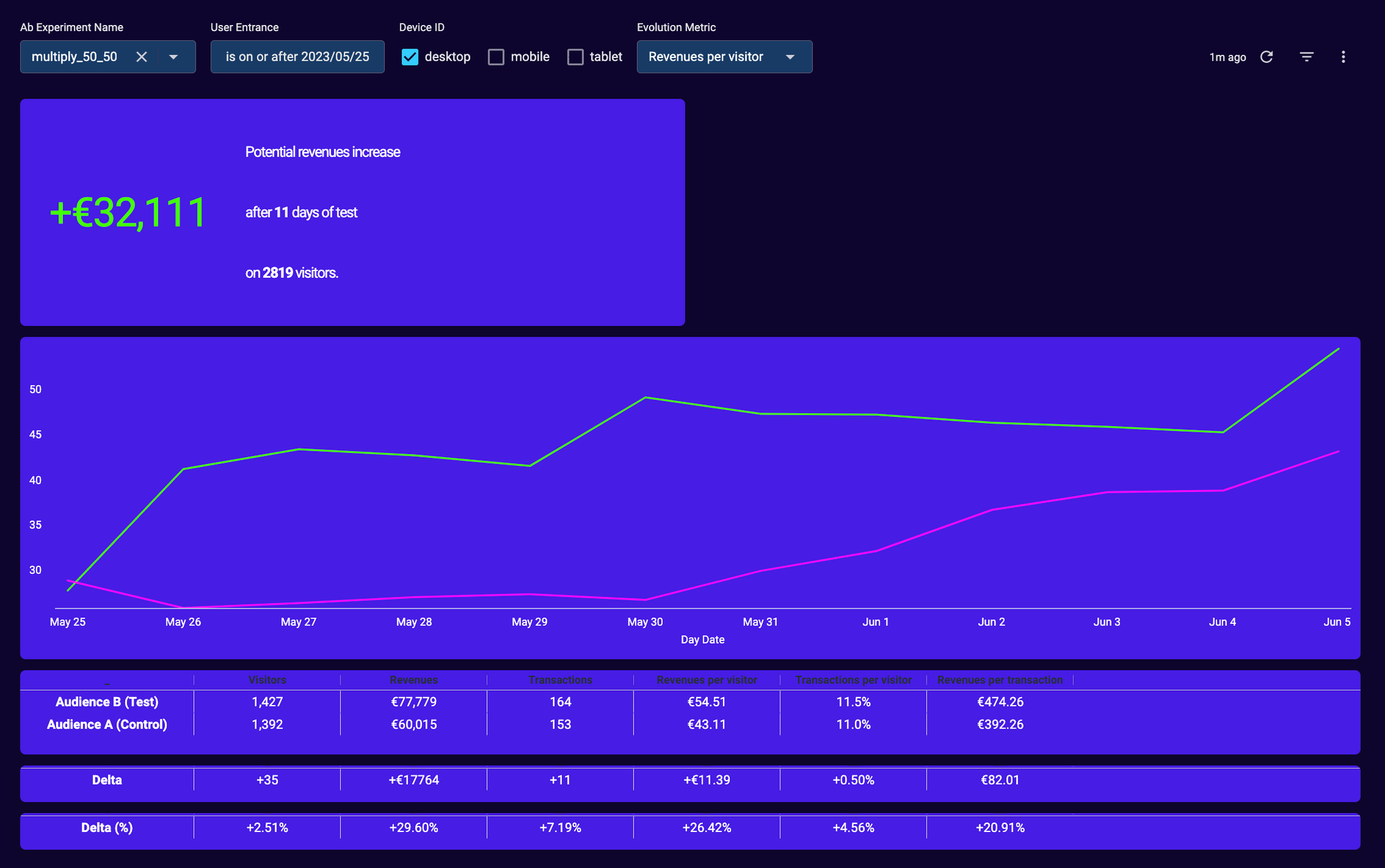
Ici le calcul est
Potentiel = (1427+1392)*54.51€ - (1427+1392)*43.11€ = (1427+1392)* 11.39€ = 32111€


Pour aller plus loin
NB#1 - Pourquoi mesurer les résultats par type d’appareil ?
La répartition dans l’audience A ou B est indépendant de l’appareil sur lequel l’internaute se trouve ainsi on peut avoir dans l’audience A :
40 desktop, 50 mobile et 10 tablette
et dans l’audience B
50 desktop, 40 mobile et 10 tablette
Or la valeur moyenne d’un visiteur dépend très fortement du type d’appareil sur lequel il se trouve : mettons 40€ sur desktop, 5€ sur mobile et 0 sur tablette.
Quand bien même les visiteurs des groupes A et B verraient la même chose, l’AB test avec les répartitions précédentes, montrerait une valeur par visiteur globale de
(40*40+50*6+0*10)/100 = 19€ par visiteur de l’audience A
(50*40+40*6+0*10)/100 = 22,4€ par visiteur pour l’audience B
Le potentiel serait alors de (22,4-19)*200 = 680€ sur 200 visiteurs !
Pour corriger des effets d’ordre 1 liés au mix de type d’appareils dans chaque groupe, il convient donc toujours de réaliser les calculs de potentiel par type d’appareil.
NB#2 - AB tests en parallèle, en cascade ou en série ?
Le raisonnement ci-dessus devrait aussi pouvoir s’appliquer à d’autres facteurs qui ont un impact de premier ordre sur la valeur de chaque utilisateur, et dont la répartition dans chaque groupe A ou B risque de biaiser les résultats d’un AB test.
Prenons un exemple courant : est-il souhaitable ou possible de réaliser plusieurs AB tests en parallèle ?
Admettons qu’un premier AB test soit en ligne, dont les résultats sont très significativement positifs pour le groupe B : les visiteurs du groupe B dépensent en moyenne 50% de plus que les visiteurs du groupe A.
Admettons qu’un second AB test soit lancé simultanément. (groupes A’ ET B’).
Sans que A’ soit différent de B’ (aucune différence dans l’expérience entre ces deux groupes), il se peut que l’on mesure A’ >> B’, dès lors que A’ est constitué d’une part légèrement supérieure de visiteurs soumis à l’expérience B du premier AB test (mettons, 60 visiteurs de B et 40 visiteurs de A dans A’, ce qui implique 40 visiteurs de B et 60% de visiteurs de A dans B’)
Afin de mener plusieurs AB tests en parallèle, il convient donc de les effectuer “en cascade” pour s’assurer que la proportion dans tout sous-groupe lié aux AB tests successifs soit strictement équitable (dans tout sous-groupe A’ on doit s’assurer de retrouver 50% de A et 50% de B…) ce qui n’est techniquement pas simple à réaliser, SURTOUT si un visiteur peut être exposé aléatoirement d’abord à l’expérience 1 (A vs B) ou à l’expérience 2 (A’ vs B’)…..
Notre conseil : toujours mener les AB tests en série, afin de se rapprocher le plus possible des conditions idéales, c’est-à-dire “toutes choses égales par ailleurs”